Improving Language Study Observability: Number Familiarity Evaluation using the ELK Stack
Introduction
As non-native language speakers, we often have difficulties quickly responding to numbers spoken using foreign languages. To overcome this issue, we have to practice more often. However, this is a long process and we might lose confidence and patience. Is there a way to let us understand more about our ability through visualization and gamification? Probably there is one.
What's in the market
There are many apps in the market that help users to be familiar with foreign languages through dictation. Once the application pronounces the number, the user will have to answer using Arabic numerals. However, none of them provide statistical features for users to get insights.
Thoughts
How about we keep a record of the user's response? Which can be used for further studies? What should be recorded?
- language
- how many digits
- the number spoken
- the user's response time
- whether the user answered correctly
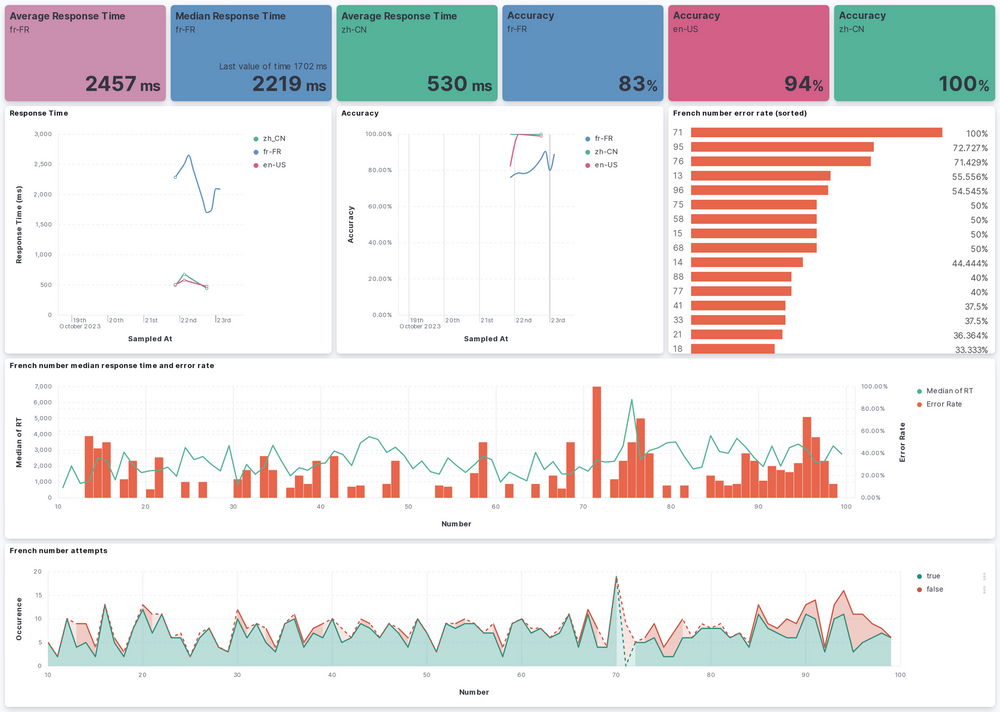
And what could be visualized
- trend of user's response time
- trend of user's accuracy
- user's average response time
- frequent mistakes the user made
Sounds good, so where to start?
Introducing the ELK stack
ELK (Elasticsearch, Logstash, Kibana) is a popular software stack for logging and analysis. Therefore, we can utilize the ELK stack to achieve this.
The user will make the answer on our front-end application. After the user answers, the metrics will be sent to Logstash via HTTP request. Logstash will process the data and save them to Elasticsearch. Then, we can use Kibana to do the visualization.
Implementation
Front-end
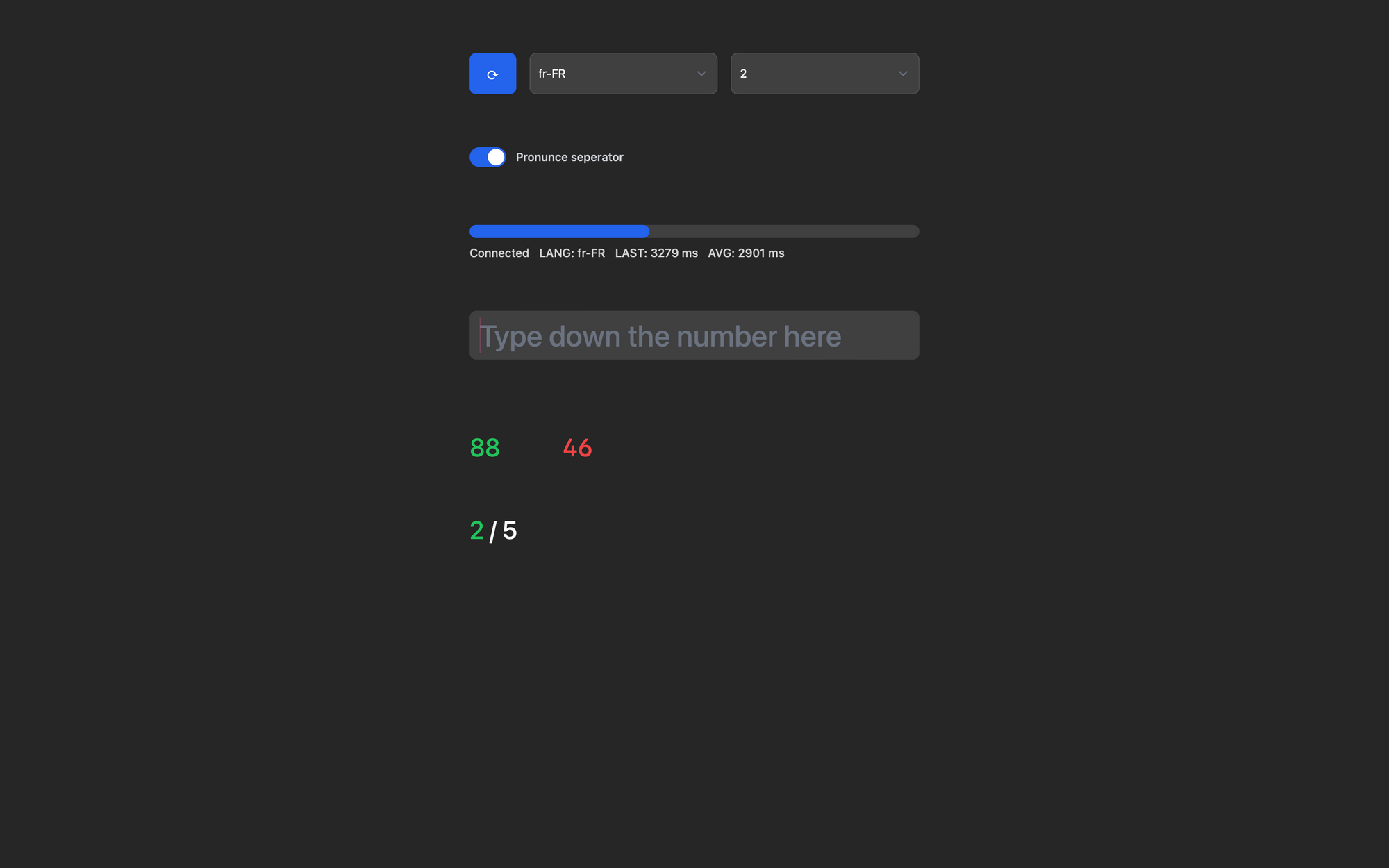
The front end is rather simple, which utilizes the SpeechSynthetis API.
const speak = () => {
var synthesis = window.speechSynthesis;
// Get the first voice in the list
var voice = synthesis.getVoices().filter(function (voice) {
return voice.lang === language.value;
})[0];
let number = currentNumber.value;
if (pronunceSeperator.value) {
number = addThousandSeperator(number);
}
// Create an utterance object
var utterance = new SpeechSynthesisUtterance(number);
// Set utterance properties
utterance.voice = voice;
utterance.pitch = 1.5;
utterance.rate = 1.25;
utterance.volume = 1;
// Speak the utterance
synthesis.speak(utterance);
utterance.onend = startTiming;
};One caveat discovered is when pronouncing four-digit numbers using en-* languages, it will pronounced by each two digits. The workaround is to add number separators:
const addThousandSeperator = (number) => {
return number.toString().replace(/\B(?=(\d{3})+(?!\d))/g, ",");
};To get precise time, the performance.now() will be used. Once the utterance end, it will get the current performance timing, and once user entered, the delta between two time will be calculated to get the user's response time.
stats.performanceMs = BigInt(
(performance.now() - stats.startPerformanceMs).toFixed(0)
);The data sent to Logstash is constructed using the following:
record.value.push({
lang: language.value,
number: currentNumber.value,
time: stats.performanceMs,
isCorrect: currentNumberInput.value == currentNumber.value,
date: new Date().toISOString().slice(0, 10),
digits: currentNumber.value.length,
});ELK
For the ELK side, we use docker-elk to set up the ELK stack. After setting up, we will add a pipeline in the logstash/pipeline directory.
input {
http {
port => 8898
response_headers => {
"Access-Control-Allow-Origin" => "*"
"Content-Type" => "text/plain"
"Access-Control-Allow-Headers" => "Origin, X-Requested-With, Content-Type, Accept"
}
}
}
filter {
split {
field => "data"
}
mutate {
convert => ["time", "integer"]
}
mutate {
convert => ["number", "integer"]
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
user => "logstash_internal"
password => "changeme"
index => "numeric"
}
}Then, we have to configure the permission and role inside Kibana. After that, Logstash is able to collect the metrics for elastic search. And it is time for us to create visualization. Below is the metrics that I found useful. The metrics for using native language served as a baseline for comparison.
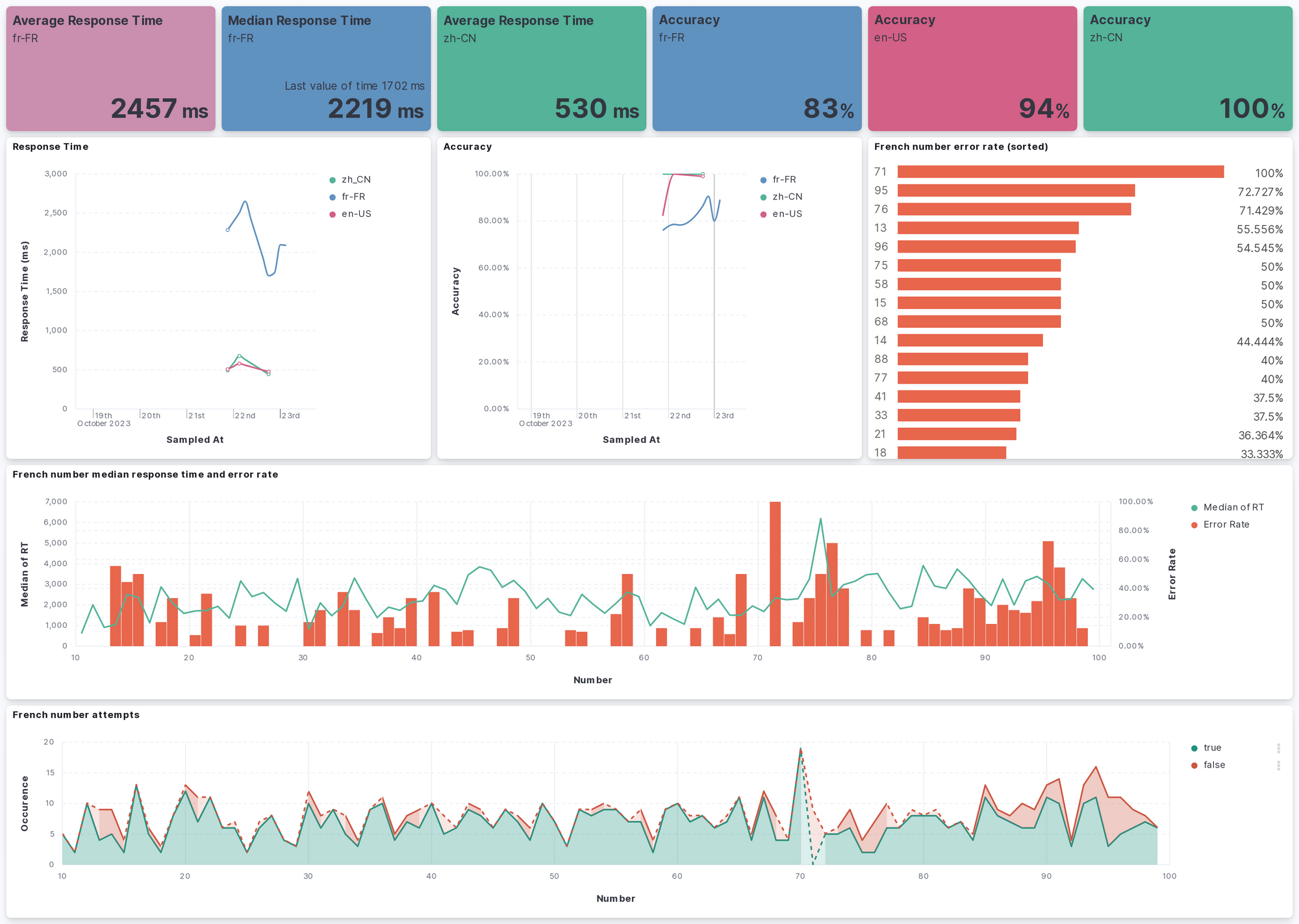
For the number error rate, the TSVB should be used to allow sorting using the error rate, which is derived from custom query.
 dodaydream
dodaydream